What is it that actually delay our deliveries? What makes people plan for a delivery to take a certain amount of time, and then it takes 3-5 times as long to get them? Is the problem that people are lazy and don’t do what they should? That they are not productive enough? Is it that we are bad so bad at planning and that we need to be even more detailed in our plans to succeed?
No, it’s often about completely different things. What we are trying to deliver is often solutions to complex problems and therefore we can not plan our way to success. Instead we have to try things out to see what works or not. Then detailed plans quickly become obsolete. People are not the problem either. They work on it as best they can, but there are other system “errors” that affect us to a very large extent.
Download our canvas with the 5 anti patterns for free >
The biggest system “errors” for delayed deliverys are
- Queues
- Batch-size
- Variation
- Task-switching/Multi-tasking
- Handovers
These are the most common reasons why our deliveries are delayed and why people get frustrated and stressed. If the system is set up so that queues are formed, we work with large batches, many variations, and we are forced to task-switch often and pass things on to others – then it is difficult even for those who do their best to deliver on time. Most organizations start several initiatives at the same time. This forces people into task-switching, it builds up queues and it creates variations. In addition, people work in silos, which means that we get a lot of handovers between people, teams, etc. and here, too, people are forced to task-switch and queues are forming.
I will explain them one by one, in more detail, and why they delay deliveries and make forecasting difficult.
Queues

We start with queues. Queues can take many different forms. It is easy to see when people are queuing in a store, or on the highway, but it is more difficult to see queues of information as a queue. A backlog is a queue – of a bunch of different results we want to achieve, customer needs we want to satisfy. Just as a list of activities to perform is also a queue.
The problem is often that people don’t realize it’s a queue. What do we do when queues occur? Well, in the store we open more checkouts to get rid of the queues. On the motorway when queues have been created due to accidents, it is required that we divert the traffic on to other roads to get rid of the queues. But what do we do with a backlog that has grown too long? In most cases nothing is done I would say. Often it just keeps growing and growing, and those who are supposed to deliver from it don’t have the capacity do the work at the same speed as the backlog grows. Then we have created a queue. Queues contribute to the biggest delays and often result in long wait. Queues make the system unpredictable and queues will always form. Just look at the highway how queues form due to different variations in driving styles. Someone drives fast, others brake violently, someone pulls out suddenly, others drive more slowly, etc.
Just now I said that queues are managed by opening multiple checkouts or redirecting traffic, and this is required because once we create a queue the system become slower. It’s easy to see on the highway when all the cars are crawling along, or if you look at customers in the store who have to wait an unreasonable amount of time to pay for their goods. So if we want the teams to be faster, keep the backlog short. Delete what doesn’t need to be done. Then you can keep a good flow in the team. In every system there is a limit to when we maintain a high flow. When the limit is reached and queues are formed, the throughput speed has also been reduced. This means that the speed will remain low and stay in that state, unless the queue is emptied. Often the speed the team could have is halved by a long queue. When the queue is empty, you have to experiment and see where the limitation is for when the flow goes down to find the bottleneck.
When we forecast, we don’t usually include queues as a risk factor. But if someone asks you when you think you’ll get home from work, we often look at the clock and say “it’s 5:30pm, so there will be queues. I’ll probably won’t be home until 6pm”. Here we clearly see that delivery time can be predicted by the fact that queues have formed in the system. When doing delivery work, we need to look for queues between teams, between silos, workstations, backlog length, etc. Then we can make sure to eliminate them as much as we can to get to the finish line faster.
Batch-sizes
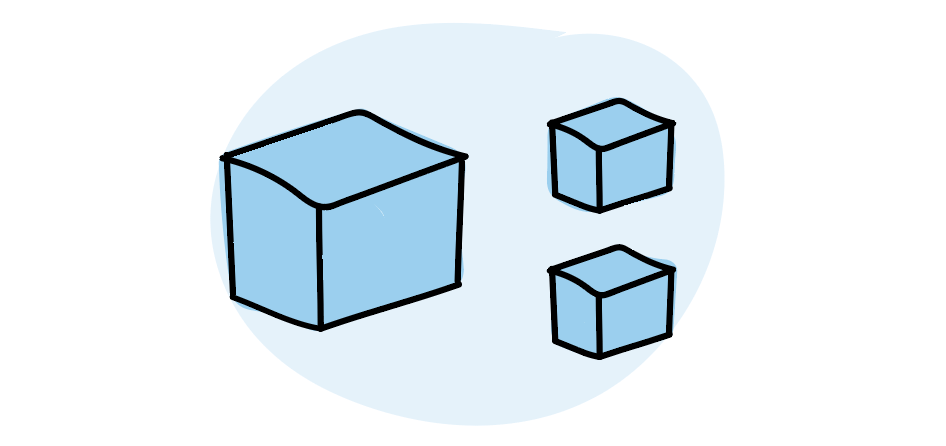
Batch-size is another thing that plays a big role in the speed of delivery. Reducing the size of what needs to be done makes it more predictable. Small things have small variations, big things have large variations, and we want as little variation as possible to make deliveries predictable.
What do I mean by that? Well, if I’m going to change a sentence of a larger text, it’s a small batch, fairly predictable without much variation. I know exactly what to change, I just need to do it. If instead I have to write a research report that several different researchers have to review and approve, then it is a large batch, which is much more difficult to predict how long it will take and when it will be finished. We simply have a lot of factors at play here that are not that predictable. For example, I don’t know how my text will be perceived by all the different researchers who will review it, if it is considered to contain the right parameters, if all the text is in the right order and is structured correctly, if the research is considered sufficiently well-founded, etc.
We can also easily see that batch sizes matter when we for example have to guess how long it takes to run 400 m, compared to guessing how long it takes to run 1 mile. If we look at 400 m as a small batch, then the variation within which I and other people manage to run 400 m, will be less than the variation when I guess how long it takes to run 1 mile.
The smaller batches we divide our work into, the less variation there will be and the more predictable it will be. Therefore, we divide our work into smaller parts that still creates value for our customers.
(more…)